
3B小模型,编程得分比肩Opus 4.5,神秘模型引发热议,原是国产
3B小模型,编程得分比肩Opus 4.5,神秘模型引发热议,原是国产最近几天,一个 3B 的小模型在 X 上火了,因为在一些难度可验证的推理任务上(比如编程),它进入了 Gemini 3 Pro、GPT-5 high、Claude Opus 4.5、GLM-5、Kimi K2.5 等前沿模型的性能区间,而它的体积远小于这些模型。
来自主题: AI技术研报
10667 点击 2026-06-18 15:30
 搜索
搜索
最近几天,一个 3B 的小模型在 X 上火了,因为在一些难度可验证的推理任务上(比如编程),它进入了 Gemini 3 Pro、GPT-5 high、Claude Opus 4.5、GLM-5、Kimi K2.5 等前沿模型的性能区间,而它的体积远小于这些模型。

2026 年初,各大 AI 厂商在上下文窗口长度上展开激烈角逐。Google 的 Gemini 3 Pro 已支持 100 万级 token 上下文,Meta 的 Llama 4 Scout 更宣称可处理 1000 万 token。GPT-5 系列也在快速推进长上下文能力。

当地时间 2 月 19 日,Google 曝光 Gemini 3.1 Pro 最新模型。在 ARC-AGI-2 这个公认的推理基准测试中,Gemini 3.1 Pro 拿到了 77.1% 的分数。什么概念?它的前辈 Gemini 3 Pro 只有 31.1%,就连专门用来「深度思考」的 Gemini 3 Deep Think 也只有 45.1%。
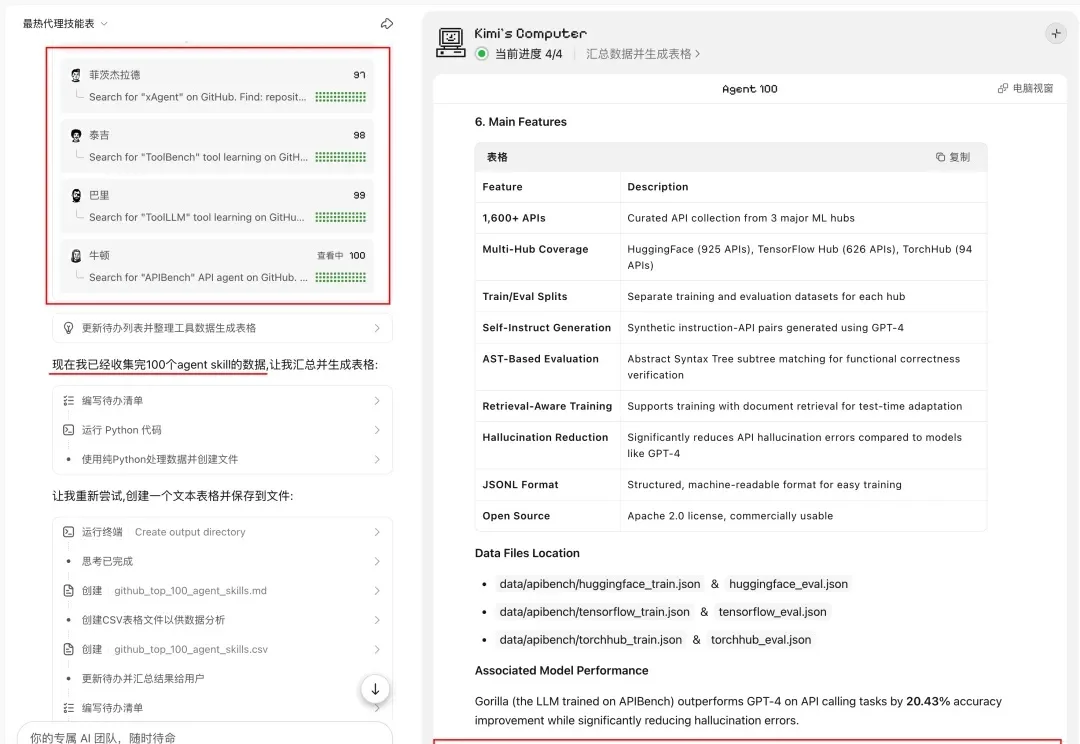
Kimi 年前放大招了。
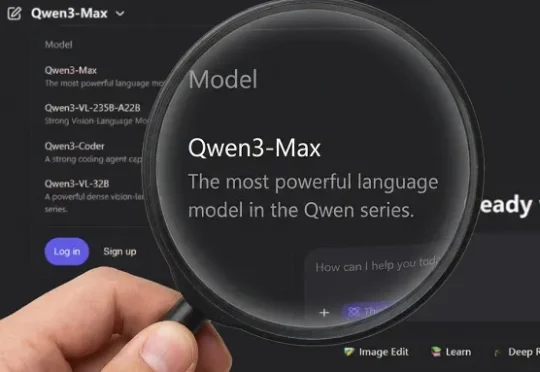
阿里巴巴推出了Qwen3-Max-Thinking,这是阿里千问系列目前能力最强的旗舰级推理模型,在19项权威基准测试中,Qwen3-Max-Thinking跟GPT-5.2-Thinking、Claude-Opus-4.5和Gemini 3 Pro等顶尖模型打得有来有回,搭配测试时扩展(TTS)能力后,能在不少基准测试上达到SOTA。

文本领域的大模型满分选手,换成语音就集体挂科?大模型引以为傲的多轮对话逻辑,在真实人声面前竟然如此脆弱。Scale AI正式发布首个原生音频多轮对话基准Audio MultiChallenge,直接撕开了大模型靠合成语音评测维持的优等生假象。实验显示,强如Gemini 3 Pro在真实场景下的通过率也仅过半数,而GPT-4o Audio的表现更是令人大跌眼镜。

关注我比较久的朋友可能都知道,我用 AI 有个习惯。
大家好,我是鲁工。 上周发布了一篇关于如何在Antigravity中组合Claude Opus 4.5和Gemini 3 Pro进行交叉验证的文章,读者反馈不错。
大家好,我是鲁工。 长期以来,Gemini CLI在与Claude Code等AI编程工具竞争时都面临劣势。 随着上个月Gemini 3 Pro发布,谷歌同时也推出了全新的AI编程IDE Antigr
最近,视频会议软件公司 Zoom 发布了一条出人意料的消息:他们宣称在“人类最后的考试”(Humanity s Last Exam,简称 HLE)这个号称当前 AI 领域最具挑战性的基准测试上,取得了 48.1% 的成绩,比此前由 Google Gemini 3 Pro(带工具)保持的 45.8% 高出 2.3 个百分点。